


NVDA GTC2024 - 資料中心即晶片 (The Data Center as a Giant Chip)
Blackwell 架構的效能超強,但沒有 NVLink 與 NVLink Switch 就沒有 GB200 NVL72;當 Moore's Law把晶片越縮越小以提升效能,Jensen's Law 用 NVLink 把整個資料中心都變成一顆晶片!另外,NVIDIA 先創 AI Factory 市場、再提 AI Cloud 市場,是否已瞄準 Cloud 市場的 400 億 Ethernet 大餅?


We build this vertically integrated thing, but we build it in a way that can be disassembled later and for you to buy it in parts, because maybe you want to connect it to x86. Maybe you want to connect it to a PCI-Express fabric. Maybe you want to connect it across a whole bunch of fiber optics.
Jensen Huang at GTC24 Financial Analyst QA

【看圖說故事】算力擴展跨系統、跨節點,效能問題就不光是去計算一個節點內的 CPU、GPU、AI 晶片的總算力那麼簡單;因此 NVIDIA 的佈局,從晶片( GPU 和 CPU) 延伸至整體機櫃,從晶片間的連接 (NVLINK),延伸至節點對節點 (NVLINK Switch)、伺服器與伺服器 (Optical、Cable、Infiniband、Ethernet),產品線覆蓋整個資料中心,達到資料中心即晶片 (The Data Center as a Giant Chip) 的境界,用 CUDA 滿足開發者需求,軟體應用滿足個別產業的需求,深入到全球的各行各業;
NVIDAI 的硬體產品,主要是增加自家產品的完整性,去補強 AI 生態系,但卻總是不小心去侵略到客戶 (如 CSP ) 的業務,而 Spectrum-X800 Ethernet 也可能打擊到以 Ethernet 為主的硬體廠商,如 CSCO;
FY23 CSCO 的網路硬體營收約為 346 億,平均單季約為 90 億,相關硬體包括 交換器 (Switch)、路由器 (Router)、無線、5G、晶片、光學解決方案和運算產品;儘管在 Ethernet Switch 市占率下降, CSCO 仍是全球第一, Ethernet Switch 單季營收規模至少有 40 億美元,按照 IDC 的數字, 前五大 Ethernet Switch 廠商的營收單季接近 120 億美元,CSCO 控制著將近 1/3 的全球市場;全年的 Ethernet Switch 市場規模超過 400 億,對於 NVIDAI來說,是一塊大餅;
NVIDAI 的 FY25Q1 網絡收入高達 32 億美元,多半來自於 InfiniBand (短時間內已快追上 CSCO 的 40 億),CFO - Colette Kress 不僅看好 InfiniBand ,更看好 Spectrum-X 將為 NVIDIA 網路開啟一個全新的 Ethernet Switch 市場,預估將在一年內躍升為價值數十億美元的產品線;

參考文章:
Nvidia’s Optical Boogeyman – NVL72, Infiniband Scale Out, 800G & 1.6T Ramp
The Data Center is the New Compute Unit: Nvidia's Vision for System-Level Scaling

Blackwell 新架構:Blackwell 的優勢,並非因為 Grace CPU 更好,而是因為在 Grace Blackwell 的架構下,能創建一個更大的 NVLink 網域 (NVLink domain);
更大的晶片:專為資料中心處理生成式 AI 而設計的 GPU;
採用台積電 4NP 製程,2.08 兆個電晶體構成,是目前全球最大的GPU;
每顆裸晶的尺寸,是現今半導體製程中光罩的極限;
Chiplets design 突破單晶片性能瓶頸限制,使用多顆小晶片組合而成,解決單顆規模限制,同時保留單顆效率,以建立更為強大的運算平台;

NVLink 互連技術:將 2 顆裸晶 (Die) 連接;
透過頻寬高達 10 TB/s 的 NV-HBI(NVIDIA High-Bandwidth Interface)晶片對晶片互連(Chip-to-Chip Interconnection)相連;
讓 2 組裸晶成為單一晶片,可確保記憶體一致性(Coherent),能夠共享容量高達 192 GB的 HBM3e 高頻寬記憶體;
GPU 可以直接訪問另一顆 GPU 的記憶體,而無需通過 CPU 或 PCIe 匯流排進行資料傳輸,可以提升傳輸速度;也因為 GPU 之間的資料傳輸可以直接進行,因此無需 CPU 參與, CPU 的負擔被減輕,讓 CPU 可以專注於其他任務,例如資料預訓練和後微調,從而提高整體系統性能;
接著,再使用 NVLink 高速連接 576 顆晶片,相當於單一大型晶片,軟體無法區分。未來可以利用 InfiniBand 等技術進一步擴展系統規模與計算能力;
優化網絡:更大的晶片 + NVLink 互連技術,還要有更好的網路, 才能夠有更大規模、更高效的 AI 系統
晶片尺寸和互連技術,是提高性能的關鍵:盡可能做大晶片,並使用 NVLink 與 NVLink Switch
進行高速互連,是提高 AI 計算性能的有效途徑;
網絡技術需要與時俱進:隨著系統規模的擴大,需要採用 InfiniBand 或增強型Ethernet 等技術來應對資料傳輸的挑戰;晶片在橫向擴展時,如果數量越多 (上千、上萬、上十萬、上百萬),但性能卻無法呈現線性成長,即代表網路技術不夠強!
避免性能瓶頸:通過網絡優化和流量控制,確保所有任務都能即時完成,避免被一個較慢的任務拖累整個系統;如果能夠用軟體更新來進一步加速,不僅有利於新的 GPU,也可以提升客戶的舊 GPU 的性能,客戶可以省下一筆錢;
【看圖說故事】為什麼 NVLink 和 NVLink Switch Chip 那麼重要?
因為 AI 運算的架構不一樣,AI 關注在最後一個 GPU的效能,不能讓最後一個 GPU 拖累整體效能,所以 AI 必須讓所有的 GPU 都可以互相溝通;現在的 x86 與 Ethernet 還做不到這件事情,因為基礎架構不一樣;
當 GPU 與 GPU 透過 NVLink 相連後,NVLink 更進一步讓兩顆 GPU 也與 CPU 相連,讓三顆晶片合而為一 (Superchip),運作方式就好比一顆晶片一樣;
下一步就是讓不同 Node (節點) 中的 Superchip 再互連成為一顆晶片,因此就換 NVLink Switch Chip 上場;

The benefit of Blackwell in that case wasn't because the CPUs better.
It's because in the case of Grace Blackwell we were able to create a larger NVLinked domain.
And that larger NVLinked domain is really, really important for the next generation of AI.
The next three years, the next three -- five years, which is, as far as we can see right now. If you really want a good inference performance, you're going to need NVLink.
That was the message, I was trying to deliver. And we're going to talk more about this. It's abundantly clear now, these large language models, they're never going to fit on one GPU.
Jensen Huang at GTC24 Financial Analyst QA


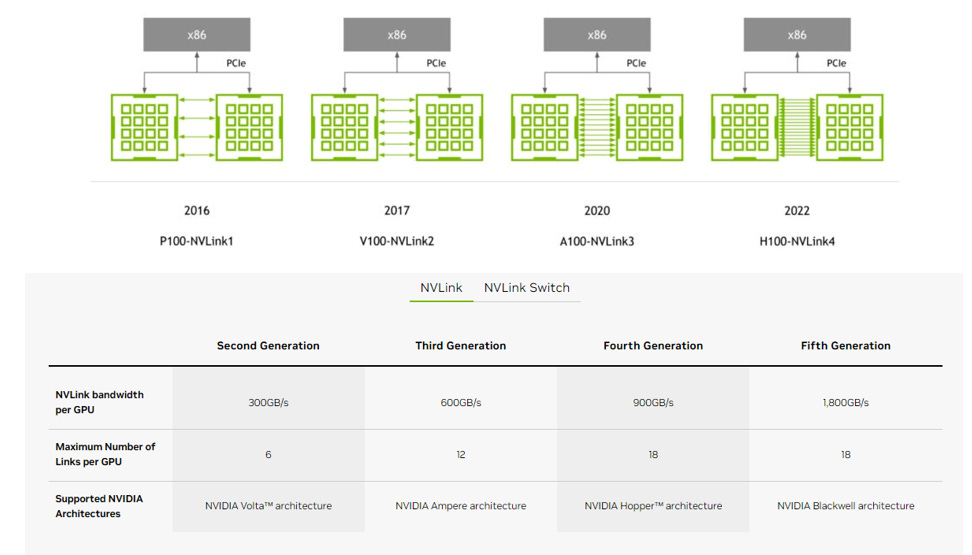
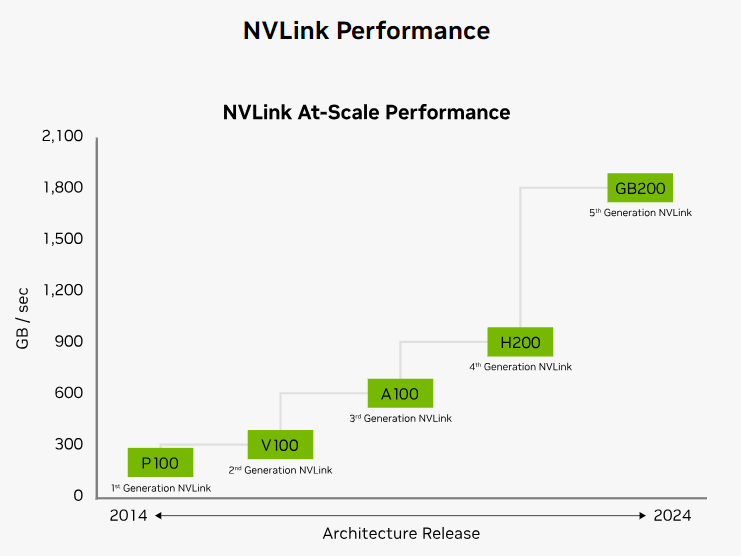
第 5 代 NVLink:Chip to Chip, C2C
第 5 代 NVLink:單晶片可支援 18 Links,單 Links 可實現 100 GB/s 的雙向頻寬,共 1,800 GB/秒,是 第 4 代 的 2 倍,第 2 代的 6 倍;PCIe Gen5 的 14 倍;
第 4 代 NVLink:單晶片可支援 18 Links,單 Links 可實現 50 GB/s 的雙向頻寬,共 900 GB/秒,第 2 代的 3 倍;
第 3 代 NVLink:單晶片可支援 12 Links,單 Links 可實現 50 GB/s 的雙向頻寬,共 600 GB/秒,是 第 2 代 的 2 倍
第 2 代 NVLink:單晶片可支援 6 Links,單 Links 可實現 50 GB/s 的雙向頻寬,共 300 GB/秒;
第 1 代 NVLink:單晶片可支援 4 Links,單 Links 可實現 40 GB/s 的雙向頻寬,共 160 GB/秒;
【看圖說故事】GPU 可以直接訪問另一個 GPU 的記憶體,而無需通過 CPU 或 PCIe 匯流排進行資料傳輸。也因為 GPU 之間的資料傳輸可以直接進行,而無需 CPU 參與,可以減輕 CPU 的負擔,這使得 CPU 可以專注於其他任務,例如資料預處理和後處理,從而提高整體系統性能;
根據 黃仁勳在 COMPUTEX 2024 上宣布的路線圖, 2026 年將推出 NVLINK 6 Switch,雙向頻寬可來到 3,600 GB/秒,又比第 5 代 NVLink 的 1,800 GB/秒 增加一倍!
【看圖說故事】下一步就是讓不同 Node (節點) 中的 Superchip 再互連成為一顆晶片,因此就換 NVLink Switch Chip 上場;

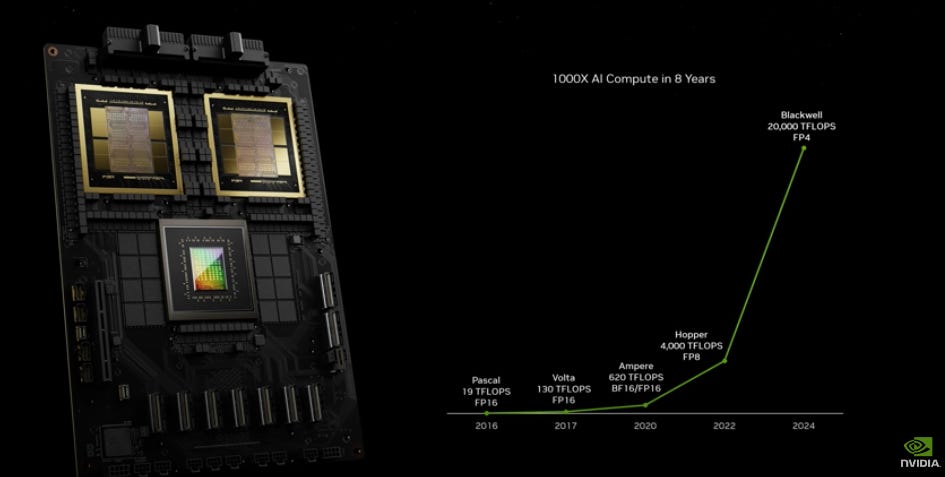
100 times every 10 years at the in the middle of the hay days of the PC Revolution.
And the last 8 years we've gone 1,000 times, we have two more years to go and so that puts it in perspective.
The rate at which we're advancing computers insane and it's still not fast enough
So we built another chip, this chip is just an incredible chip, we call it the NVLink Switch
Jensen Huang at GTC24


NVLink Switch Chip:Superchip to Superchip
擁有 500 億電晶體的晶片;(Hopper GPU 有 800 億電晶體)
4 條 NVLink ,每條雙向頻寬可來到 1,800 GB/秒;
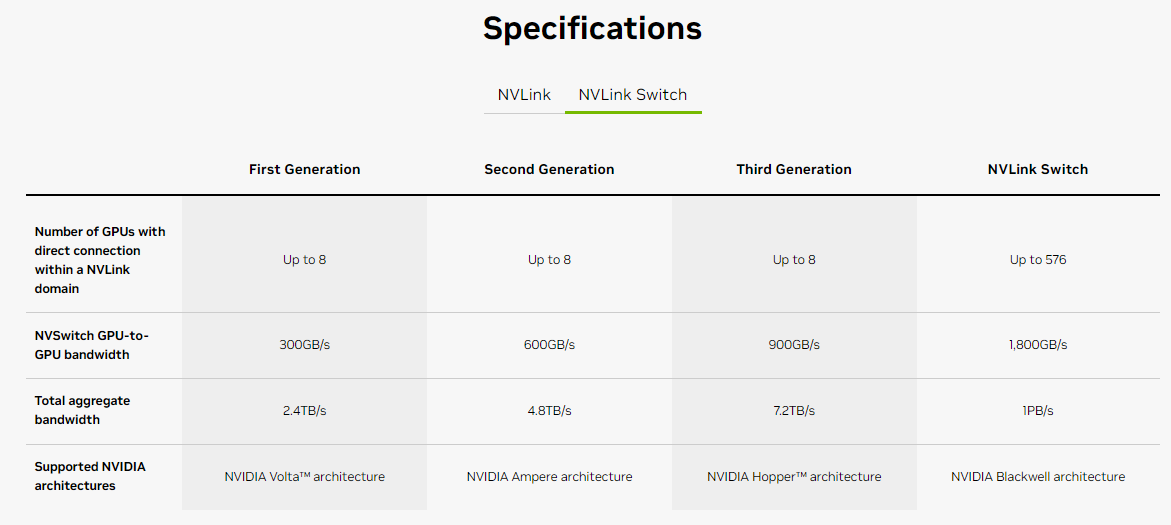
NVLink Switch 允許 NVLink 跨節點擴展;借助 NVSwitch,NVLink 可在節點間擴展,以創建無縫、高頻寬的多節點 GPU 集群,從而有效地形成資料中心大小的GPU;
可以讓所有 GPU 同時以全速互相通訊,將多個 GPU 連接成一個巨大 GPU,大幅提升運算能力;
為了降低成本,NVLink Switch Chip 可以直接使用銅線,無需昂貴的光纖;



節點 (Node) 與 NVLink Switch 的連接 :用銅纜取代光纖
因為節點與節點間的距離不長,對傳輸速度的要求仍不算高,所以目前使用銅線去連接 NVLink Switch 仍綽綽有餘;
以 DGX GB200 NVL72 來說,共需要 5000 根的 NVLink Cable ,總長 2 英里,但是銅纜比光纖便宜,也更節能;
因為可省下 2 萬瓦因為光纖的 transceiver 和 retimer 而消耗掉的電力;整個 GB200 NVL72 機架是 12 萬瓦,可因為使用 NVLink Cable 而降到 10 萬瓦 (省下來的電力可以移做資料處理);
QYResearch:預計 2029 年全球高速直連銅 (DAC) 電纜市場規模將達 17 億美元,CAGR 達 12.3%;
一台 NVL72 將使用約 5000 根銅纜(共計 2 英里),進行 NVLink Switch 和 GPU 之間的連接,高速銅纜逐漸爲更多元化的高速傳輸場景提供更多解決方案;
【看圖說故事】不過,未來光纖技術仍有很大的需求和應用空間,在 2024 年的 COMPUTEX 上,技嘉的解說人員表示,儘管黃仁勳是推薦使用銅線,但多數客戶還是偏好光纖,但不確定是真是假;
退一步來看,用銅纜取代光纖,並不會影響光通訊元件的用量,因為離開資料中心,主要還是需要光纖去做傳輸,好用最快的速度將資料傳輸到離終端使用者最近的地方;
【看圖說故事】GTC24 的重頭戲為,利用 NVLink Switch 可以一次連接 72 顆 GPU,同時以全速互相通訊,大幅提升運算能力,這顆巨大無比的 GPU 名為 DGX GB200 NVL72!

The first DGX delivered to OpenAI is 0.17 petaFLOPS, so this is 720 petaFLOPS (PFLOPS, 1015 ) , almost an exaFLOPS (EFLOPS,1018) for training, and the world first exaFLOPS machine in one rack.
Just so you know, there are only a couple 2-3 exaFLOPS machines on the planet as we speak, and so this is an AI system in one single rack. Well, let's take a look at the back of it.
So this is what makes it possible, that's the back, the DGX NVLink spine 130 TB per second goes through the back of that chassis that is more than the aggregate bandwidth of the internet, so we could basically send everything to everyone within a second.
Jensen Huang at GTC24

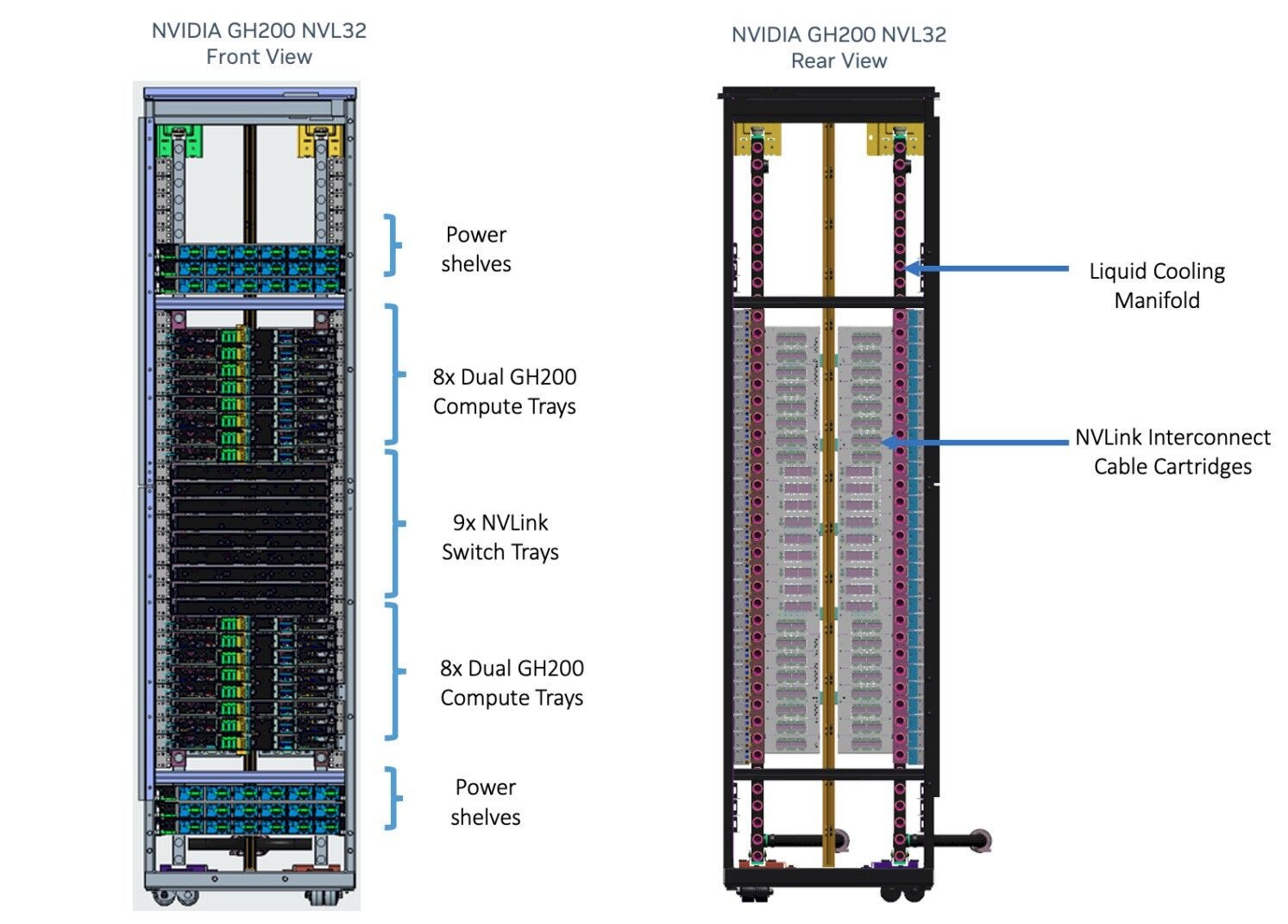
GB200 NVL72
18 層 1U 伺服器,共可連接 36 顆 Grace CPU (18*2) + 72 顆 Blackwell GPU (18*4);
上 8 層: (下圖是 H200 示意圖,但基本結構不變)
每層有 2 顆 GB200 Grace Blackwell Superchip (每 1 顆 Superchip是透過 NVLink -C2C 將 2 顆 Blackwell GPU 與 1 顆 Grace CPU 連接);
還有 ConnectX-8 superNIC 或 BlueField-3 superNIC;
中 9 層:
每層有一個 NVLink Switch (透過 NVLink Switch 將上 8 層 與 下 8 層 連接);
第四代的 NVLink Switch,可用 NVLink 技術去連接 576 顆的 GPU,雙向頻寬可來到 1,800 GB/秒;前一代僅能連接 8 顆、 900 GB/秒 (Hopper 架構);
下 10 層: (下圖是 H200 示意圖,但基本結構不變)
每層有 2 顆 GB200 Grace Blackwell Superchip (每 1 顆 Superchip是透過 NVLink -C2C 將 2 顆 Blackwell GPU 與 1 顆 Grace CPU 連接);
還有 ConnectX-8 superNIC 或 BlueField-3 superNIC;
單一機架 - 內:以銅線的 NVLink 去互連 ( NVLink Spine);
單一機架 - 外:延續 H100 的架構,需要 2-3 層交換器網路和光通訊方案;機架可透過 Quantum InfiniBand 或 Spectrum Ethernet連接;
功耗過大,需採取液冷機架級解決方案 (地板上的紅色的高溫水管+藍色的低溫水管)





【看圖說故事】在 2024 年的 COMPUTEX上,左圖是 鴻佰的 NVL72;右圖是 技嘉的 NVL 36,曾有傳言因為 NVL72 是用 1U Tray,比較密集,因此散熱難度較高,也比較難組裝,所以許多廠都先用 NVL 36 來出貨;
但是 COMPUTEX 全場唯一使用 NVL 36 的技嘉則是說,NVIDIA 本來就出兩種規格給客戶選擇,所以也不是難度的問題,應該是要澄清技嘉並非做不出來 NVL72 吧;
(右圖:上面 5 層 2U Tray,下面 4 層 2U Tray,共 9 層,每層 4 顆 Blackwell GPU,共 36 顆 Blackwell GPU)
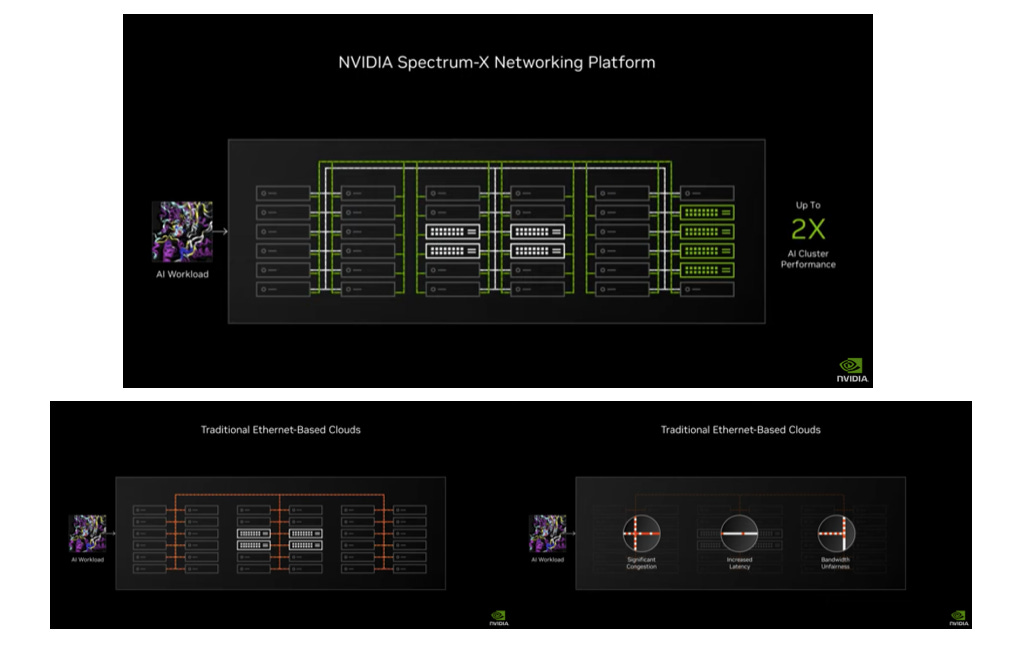
【看圖說故事】NVIDAI 想把生成式 AI 帶到每座資料中心,但並非所有資料中心營運商都有能力為了 AI 去蓋新的資料中心;而因為設備都已就位,既有資料中心要調整內部擺設的難度頗高,為減少資本支出,方便既有資料中心進行最低限度地調整,NVIDAI 就必須向前兼容,因此推出適用於 AI 的Ethernet平台 - Spectrum-X,主要是因為許多企業用的都是 Ethernet,企業要獲得 InfiniBand 的難度頗高,所以 NVIDAI 將 InfiniBand 的能力帶進 Ethernet 市場;


Even this is not big enough for AI Factory, so we have to connect it all together with very high speed networking.
We have two types of networking. We haven infiniband which has been used in supercomputing and AI factories all of the world and it is growing incredibly fast for us.
However not every data center can handle infiniband because they've already invested their ecosystem with ethernet for too long and it does take some specialty and some expertise to manage infiniband switches and infiniband networks.
So what we've done is we've brought the capabilities of infiniband to the ethernet architecture which is incredibly hard.
Jensen Huang at at COMPUTEX 2024

GB200 NVL72 to GB200 NVL72:
GTC 2024 正式發表 Spectrum-X800,也宣布用於 InfiniBand 網路環境的 Quantum-X800,成為以 X-800 為名的網路軟硬體整合解決方案,在連接不同機櫃的 GPU 時就有 InfiniBand 或 Ethernet 兩種選擇
(1) Quantum-X800 InfiniBand:Quantum Q3400 switch + ConnectX-8 superNIC + LinkX Cables + Transceivers
(2) Spectrum-X800 Ethernet:Spectrum-4 Ethernet Switch (SN5600) + BlueField-3 superNIC
2023 年 5 月首度發表 Spectrum-X,是專為設置在 Ethernet 的 AI 雲端服務所設計的解決方案;
Spectrum-X 的特殊之處,在於 RoCE 協定的適配器路由和擁塞控制,這是從 InfiniBand 借用的直接記憶體存取技術,使其延遲比其他方式更低;
對於動態路由,BlueField-3 DPU 的任務是對無序 Ethernet 封包進行重新排序,並透過 RoCE 以正確的順序將它們放入伺服器記憶體中;
Spectrum-4 總共 128 個端口,可達成的總頻寬是 51.2TB/s,和傳統的Ethernet 交換器相比高出 2 倍的有效頻寬;

【看圖說故事】NVIDAI 宣稱 Spectrum-X Ethernet 是全球首個專為 AI 設計的高效能 Ethernet 產品,因為生成式 AI 負載需要新型 Ethernet ,並不是為了和市面上那些 Ethernet Switch 競爭,因為不是為了處理常規的「mouse flow」流量,而重在處理「elephant flow」流量,目前市場上還沒有相對應的解決方案,Ultra Ethernet 還要幾年後才會推出,才有機會滿足生成式 AI 的需求,因此 NVIDAI 只好推出自己的 Ethernet 解決方案來完整 AI 生態系。
在這次的 Computex上,NVIDAI 透露 2025 年除將推出代號 Blackwell Ultra 晶片外,還有 Spectrum Ultra X800 Ethernet 晶片 (10 萬顆 GPU);(Spectrum X800 Ethernet 可以連接上萬顆 GPU)
2026 年除採用 8 層 HBM4 記憶體的 Rubin GPU 外,全新 Arm Neoverse 架構的 CPU 將命名為 Vera;NVLink 也將更新至第 6 代,還有 1,600Gb/s 的 CX9 SuperNIC,以及 X1600 系列的 InfiniBand 與 Ethernet 晶片 (百萬顆 GPU,NVIDAI 可以賺多少錢?);
【看圖說故事】儘管 NVIDAI 的硬體產品,主要是增加自家產品的完整性,去補強 AI 生態系,但卻總是不小心去侵略到客戶 (如 CSP ) 的業務,而 Spectrum-X800 Ethernet 也將打擊到以 Ethernet 為主的硬體廠商,如 CSCO。



Maybe you would like to use Ethernet. Okay, Ethernet is not great for AI. It doesn't matter what anybody says. You can't change the facts. And there's a reason for that.
There's a reason why Ethernet is not great for AI. But you can make Ethernet great for AI. In the case of the ethernet industry, it's called Ultra Ethernet. So in about three or four years, Ultra Ethernet is going to come, it'll be better for AI.
But until then, it's not good for AI. It's a good network, but it's not good for AI.
And so we've extended Ethernet, we've added something to it. We call it Spectrum-X that basically does adaptive routing. It does congestion control. It does noise isolation.
Jensen Huang at GTC24 Financial Analyst QA
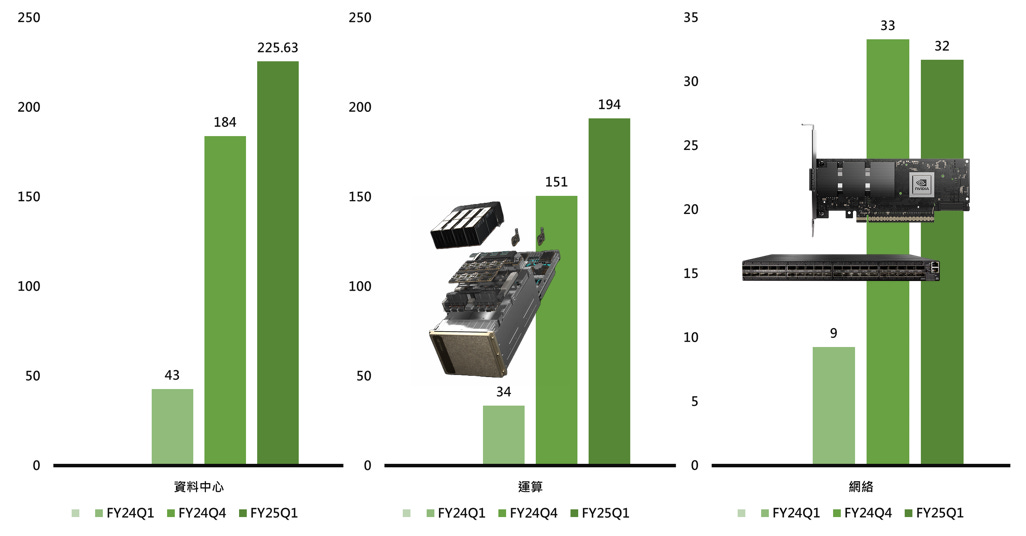
FY25Q1 ,CFO - Colette Kress:
InfiniBand 推動網路業務的強勁年成長。雖然跟前季相比出現衰退,但這主要是由於供應時間,需求仍遠遠超過所能供給的數量,預估網路業務將在第二季度恢復季增成長。FY25Q1 開始交付全新的 Spectrum-X 乙太網路解決方案,從頭開始針對 AI 進行最佳化。 Spectrum-X 包括 Spectrum-4 交換器、BlueField-3 DPU 和新軟體技術,以克服乙太網路上 AI 的挑戰,為 AI 處理提供比傳統 Ethernet 高 1.6 倍的網路效能;
Spectrum-X 正在與多個客戶合作,其中包括一個擁有 100,000 個 GPU 的龐大叢集。 Spectrum-X 為 NVIDIA 網路開啟一個全新的市場,並使僅有 Ethernet 的資料中心能夠容納大規模 AI,預估 Spectrum-X 將在一年內躍升為價值數十億美元的產品線;

【看圖說故事】在 FY25Q1 的法說會上,CFO 提到,除了 InfiniBand 推動網路業務強勁成長,Spectrum-X 還將為網路業務切入一個全新的市場 - 讓使用 Ethernet 的資料中心能夠容納大規模 AI,預估 Spectrum-X 將在一年內躍升為價值數十億美元的產品線;
FY25Q1的網絡收入高達 32 億美元,應該幾乎都與 InfiniBand 相關,或僅少部分來自於 Spectrum-X,而 Spectrum-X 若真的在一年內躍升為價值數十億美元的產品線,整個網絡業務的收入有機會翻倍成長,而 (1) Quantum-X800 InfiniBand 與 (2) Spectrum-X800 Ethernet 又多與 GPU 搭配著賣,可見得 NVIDIA 仍非常看好其 AI 市場;
【看圖說故事】NVIDIA 在以色列蓋了AI 超級電腦 - Israel-1,有 256 台 DELL 伺服器,配備 2048 顆 H100 GPU、2560 顆 BlueField-3 DPU,以及超過 80 台 的Spectrum-X800 Ethernet,NVIDIA 把 Israel-1 當作 Spectrum-X 的參考模型,讓客戶作為參考架構,但也可以看到 2048 顆 H100 需要搭配多少數量的BlueField-3 DPU 和 Spectrum-X800 Ethernet,對 NVIDIA 而言都是商機,而這個商機又有多大?
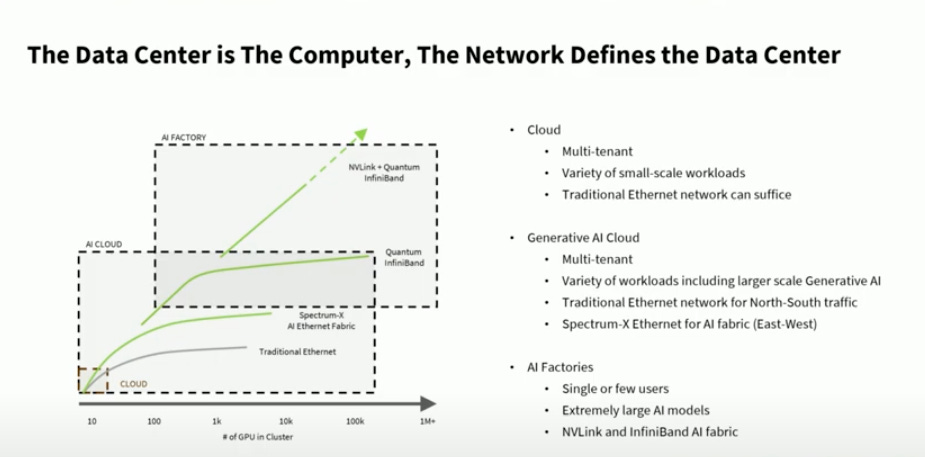
【看圖說故事】就目前的市場來看,按照使用的 GPU 數量來區分,可以分作 雲端 (Cloud),AI 雲端 (AI Cloud),AI 工廠 (AI Factory );
雲端通常有很多的租戶,使用方式或提供的服務都不同,因此多半使用傳統的Ethernet;
而教主倡議的 AI 工廠 (AI Factory ) 使用到的 GPU 數量可達上萬顆,通常就是單一租戶 (CSP 本身,如 Microsoft),也只做單一業務 (如 訓練 GPT),用 NVLINK 讓 GPU 間進行溝通,再用 InfiniBand 讓不同伺服器間進行溝通;
但是介於兩者之間的 AI 雲端 (AI Cloud) ,多半使用傳統的 Ethernet 提供 生成式 AI 服務,雖然既有的基礎設施有部分已換為高效能的 GPU,但就目前為止, 傳統的 Ethernet 仍不適合 AI GPU,因為會影響效率,因此 NVIDIA 提出 (2) Spectrum-X800 Ethernet,讓 CSP 可以提昇 AI 雲端的效率;
【看圖說故事】透過這招,NVIDIA 一隻腳正式跨進傳統雲端市場,只要這些雲端服務商想要提供生成式 AI 服務的話;
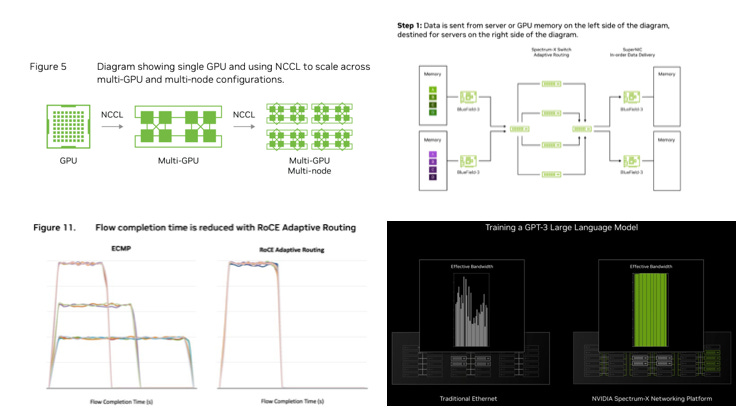
(2) Spectrum-X800 Ethernet:由 NCCL去做 RoCE 優化,實現基於無損 Ethernet 的自適應路由;還包括擁塞控制、多租戶效能隔離等技術,能將整體有效頻寬從典型的 60%提升到 95%,因此為東西向的溝通帶來大幅的效能提升。
NVIDIA Collective Communications Library (NCCL) :是一種標準集體溝通常式程式庫,用於多個 GPU 橫跨單一節點或多個節點。
RoCE Adaptive Routing (動態路由):BlueField-3 DPU 將發送到網路上的資料包 (Packet) 逐包進行最佳可用路徑的選擇,資料包會透過不同路徑傳送到接收端 - BlueField-3 DPU。這樣的好處在於可以充分利用交換器 (Spectrum-X Switch )之間的連接,讓這些資料能夠走不同的最優路徑到達接收端,提升效能。( RoCE,RDMA over Converged Ethernet )
性能隔離:AI 雲端需支援大量的租戶,用戶和應用程式產生的流量會競爭基礎架構的共享資源,因此可能會影響彼此的效能;Spectrum-X 平台包含多種機制 (RoCE 自適應路由、RoCE 擁塞控制、共享緩衝區),共同提供效能隔離,確保一個工作負載不會對其他工作負載的效能造成負面影響。
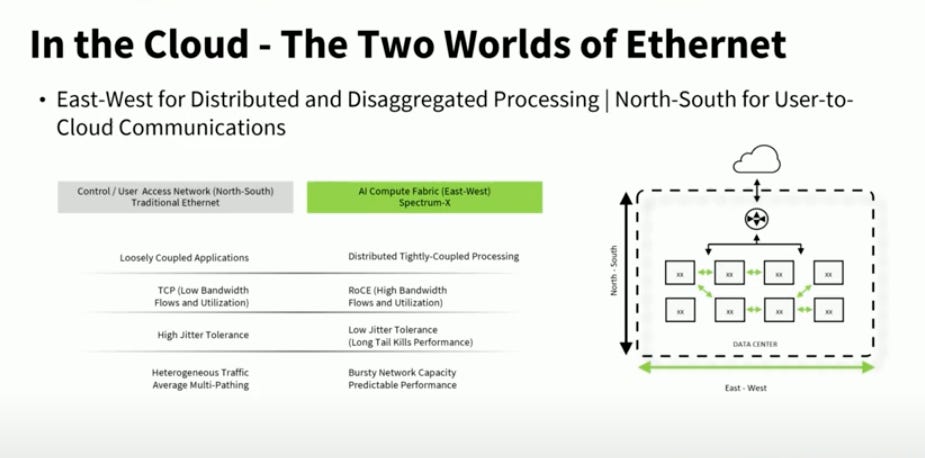
【看圖說故事】NVIDIA 所擅長的是東西向的傳導 (East - West),也就是 GPU 間的資訊傳遞與運算;
傳統 Ethernet 擅長的是南北向的傳遞 (North - South),可能是從一台伺服器傳到另一台伺服器,也可能是雲端業者將資訊傳輸到可能在地球另一端的使用者;
但在既有的 AI 雲端 (AI Cloud) 架構下,不管是東西向還是南北向都使用傳統 Ethernet,在這樣的情況下,不僅沒辦法處理東西向的資訊流,傳遞給用戶的速度也慢;
AI 應用需要低延遲,所有的數據需要同一時間抵達,好比搭飛機出國,如果最後一個人遲到了,整架飛機都不能起飛(或者是自家的阿罵還沒來,總不能丟下阿罵不管),對於使用生成式 AI 服務的使用者體驗就不好,這時候就需要 (2) Spectrum-X800 Ethernet ,既可以做東西向溝通,也可以做南北向溝通;
【看圖說故事】所以說,AI 雲端 (AI Cloud) 其實已經吃到一部分傳統雲端的市場,未來是否會直接殺進整個雲端市場也很難說,首當其衝的可能是傳統 Ethernet Switch 霸主 - CSCO;CSCO 的營收將是 NVDA 的機會。

")
【Google AI Studio】InfiniBand vs. Ethernet:
客戶不喜歡供應鏈過於集中:可能是因為超大規模供應商和雲端供應商等大公司不喜歡集中其供應鏈風險。
可擴展性較低:InfiniBand 可擴展至 10,000 - 40,000 個節點;但企業正在考慮構建具有 50,000 - 100,000 個加速器的訓練集群,甚至是 100 萬個;Ethernet 通常有更好的擴展性,而 UEC 正努力 提升Ethernet 的性能以滿足 AI 和 HPC 工作負載的需求,並提供更好的可擴展性;
成本較高:Microsoft 雖然很早就積極採用 InfiniBand 技術,還為 InfiniBand 添加許多Ethernet 的既有功能 (如允許數個用户共享资源,以及保護用户的數據和隱私等安全功能),但 Microsoft 和 Meta 等企業可能都不會願意為 InfiniBand 支付 20% 的溢價,尤其是 Ethernet 成本通常不到集群總成本的 10% (推估 InfiniBand 約達 12%,若是按百億美元來計算,還是多花了不少錢?),因為省下更多的網絡成本,就可以進一步提升運算能力;
InfiniBand 的性能優勢主要展現在大型集群:; 規模若較小,尤其是對延遲要求不敏感的應用,可能會選用適合小集群的 Ethernet。
InfiniBand 管理與維護均較複雜:性能雖強,但需要專門的知識,相對適合超大規模企業,Ethernet在 AI 集群市場中仍具有競爭力,尤其是在一般企業市場,因為其技術成熟、易於管理,並且成本更低;

【看圖說故事】
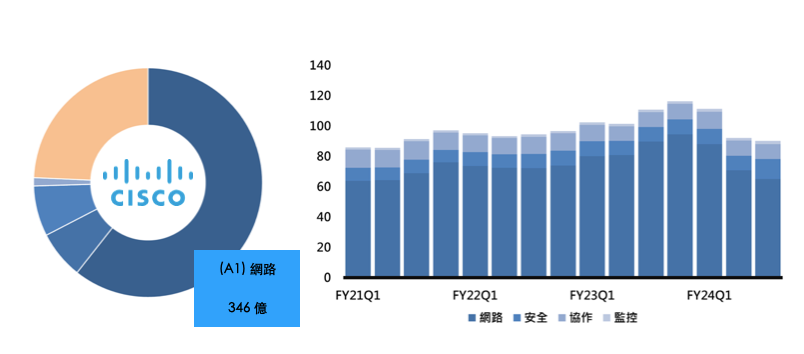
FY23, CSCO 的網路硬體營收約為 346 億美元,平均單季約為 90 億美元,相關硬體包括 交換器 (Switch)、路由器 (Router)、無線、5G、晶片、光學解決方案和計算產品;
IDC 數據顯示, 前五大 Ethernet Switch 廠商的單季營收總計約 120 億美元;而儘管在 Ethernet Switch 市占率下降, CSCO 仍是全球第一, Ethernet Switch 單季營收規模至少有 40 億美元,相當於 1/3 的全球市佔;
對 NVIDAI來說,Ethernet Switch 就是一塊大餅,連網設備搭著 GPU 來賣簡直是無敵的;
另一方面,其實也不需太為 CSCO 擔心,因為 (2) Spectrum-X800 Ethernet 雖然可以做東西、南北的溝通,但仍然以東西向的溝通為主,畢竟如何讓 GPU 之間的運算加速才是 NVIDAI 現階段最應該專注的本業;


非常有幫助,謝謝你!